What Is Image Annotation in Machine Learning? Types, Techniques and Use Cases
A computer vision model cannot tell a pedestrian from a traffic cone — unless someone first showed it the difference, thousands of times over, in annotated images. Image annotation is that process: it turns raw visual data into structured training material that teaches a model what objects look like, where they appear, and how to distinguish them from each other.
This guide covers every major image annotation technique, when each applies, how quality is measured, and the common mistakes that degrade model performance before training even starts. Whether you are building an object detection model or a pixel-level segmentation system, the annotation decisions made at the data preparation stage determine what the model can and cannot learn.
What Is Image Annotation
Image annotation is the process of adding structured labels or metadata to images so that machine learning models — primarily computer vision models — can learn from them. Annotated images form the ground truth dataset: for each image, the annotation specifies what objects are present, where they are located, and sometimes what class each pixel belongs to.
Without annotation, an image is just a grid of pixel values. With annotation, it becomes a training example: the model predicts what it sees, compares its prediction to the annotation, and adjusts its weights accordingly. Repeat that process across a large, diverse, well-annotated dataset, and the model develops the ability to interpret new images it has never seen before.
Image annotation is the foundational step in training models for object detection, image classification, semantic segmentation, instance segmentation, pose estimation, facial recognition, optical character recognition, and any other task where the input is visual.
Types of Image Annotation
The annotation type determines both the structure of the training data and the model architecture it can support. Choosing the wrong type for the task is one of the most common and expensive mistakes in ML data preparation.
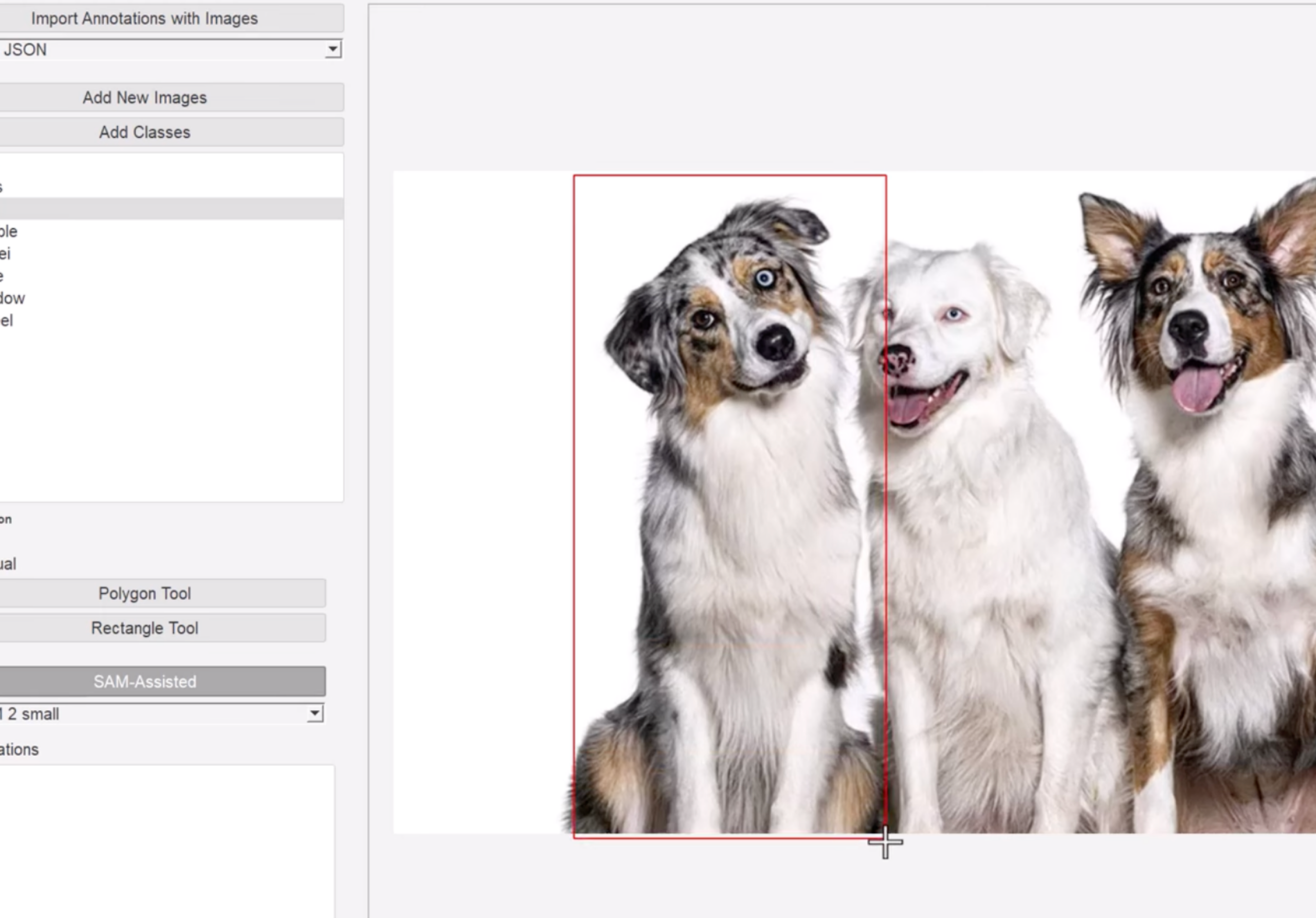
Bounding box annotation
Bounding box annotation draws a rectangular frame around each object of interest in an image. The box is defined by the coordinates of its top-left and bottom-right corners. It identifies the object’s position and class but not its precise shape.
Bounding boxes are the fastest image annotation technique and produce training data for object detection models — YOLO, Faster R-CNN, and their variants. They are appropriate when objects are roughly rectangular in shape, when they do not overlap heavily, and when precise boundary information is not required by the model.
When objects are irregular, densely packed, or when the model needs to understand exact shape, bounding boxes introduce too much background noise. In those cases, polygon annotation or segmentation is the correct choice.
Polygon annotation
Polygon annotation traces a precise outline around an object by placing a sequence of vertices that follow the object’s actual boundary. The result is a tighter fit than a bounding box, capturing the object’s real shape rather than approximating it with a rectangle.
Polygon annotation is used when shape accuracy matters — irregular objects like vehicles, trees, buildings, or medical structures where a rectangular frame would include significant background content. It is slower per object than bounding boxes and requires more annotator care, but it produces cleaner training data for tasks where shape is a decision input for the model.
Semantic segmentation
Semantic segmentation assigns a class label to every pixel in the image. All pixels belonging to the same category receive the same label — every pixel that is road gets one label, every pixel that is pedestrian gets another — without distinguishing between individual instances of the same class.
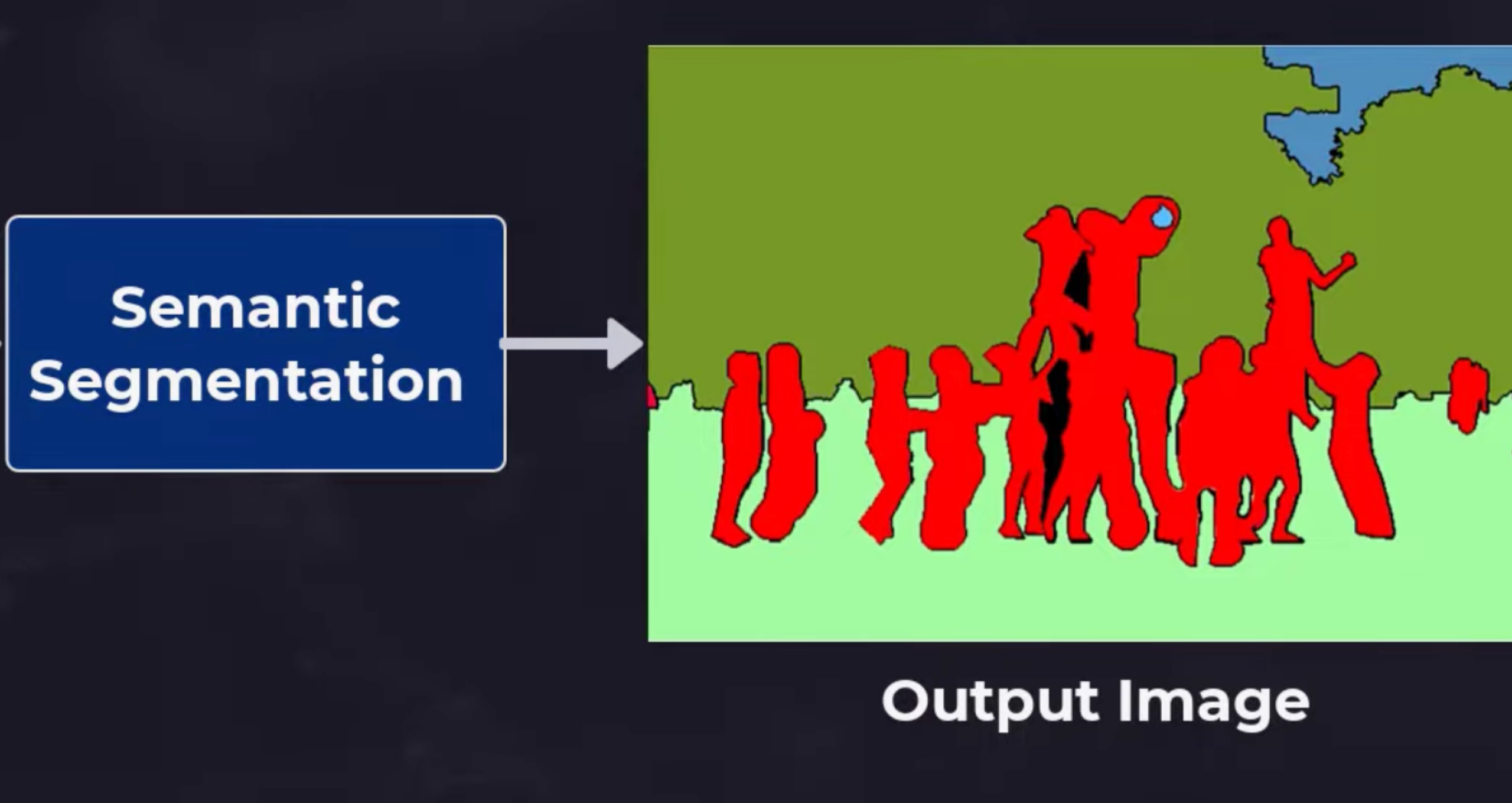
This technique is used when a model needs to understand the full composition of a scene at the pixel level. Autonomous vehicle perception models use semantic segmentation to distinguish the road surface from the pavement, identify vegetation, and classify all visible objects simultaneously. The annotation cost is high relative to bounding boxes, but the information content per image is much greater.
Instance segmentation
Instance segmentation extends semantic segmentation by assigning a unique identity to each individual object, in addition to its class. Where semantic segmentation would label two people with the same mask, instance segmentation gives each person a distinct ID.

This is necessary for tasks that involve counting, tracking, or reasoning about individual objects — crowd analysis, inventory management, surgical instrument tracking in medical video. Instance segmentation annotation is more expensive than semantic segmentation because it requires both pixel-level accuracy and object-level identity assignments.
Keypoint annotation
Keypoint annotation marks specific coordinates of interest within an object. For human pose estimation, the standard set of keypoints covers 17 body joints — shoulders, elbows, wrists, hips, knees, ankles, and facial points. For facial recognition and expression analysis, keypoints mark eye corners, mouth boundaries, nose tip, and jaw outline.
Keypoint annotation trains models to understand spatial relationships between parts of an object, not just the object’s location. Applications include pose estimation for fitness and physical therapy apps, gesture recognition for human-computer interaction, and gait analysis in sports and rehabilitation.
3D cuboid annotation
3D cuboid annotation places a three-dimensional box around an object, providing depth, volume, and orientation information that a 2D bounding box cannot encode. It is used in combination with LiDAR point cloud data for autonomous vehicle and robotics applications, where the model needs to understand the physical size and spatial position of objects in three dimensions.
Line and polyline annotation
Line annotation draws linear features — lane markings, roads, railways, utility lines, or pathways. It is simpler than polygon annotation but suited to tasks where the relevant feature is a boundary or a path rather than a closed region. Lane detection for autonomous vehicles and road segmentation for aerial imagery are the primary use cases.
Image Annotation for Computer Vision: Key Use Cases
Autonomous vehicles
Autonomous vehicle perception models depend on image annotation at massive scale. Every category of road object — vehicles, pedestrians, cyclists, traffic signs, lane markings, drivable surfaces — must be annotated consistently across thousands of driving scenarios, weather conditions, and lighting environments. The annotation market for autonomous vehicle data, estimated at $1.7 billion in 2025, is projected to exceed $14 billion by 2034 [1]. The precision requirement is safety-critical: annotation errors translate directly into perception failures.
Medical imaging
Medical image annotation labels anatomical structures, pathologies, and instrument positions in X-rays, CT scans, MRI images, and surgical video. This domain requires annotators with clinical expertise — the boundary of a tumour or the presence of a fracture cannot be reliably identified without domain knowledge. Annotation errors carry clinical stakes, which means quality thresholds and inter-annotator agreement requirements are stricter than in most other domains.
Retail and e-commerce
Product recognition, shelf monitoring, and visual search all depend on annotated image data. Object detection models trained on annotated product images enable checkout-free retail, inventory tracking, and personalised visual recommendations. The annotation task is typically bounding boxes at scale, which makes it well-suited to model-assisted annotation workflows.
Agriculture
Aerial and drone imagery annotated for crop health, weed detection, and plant counting trains models that help farmers target treatment precisely rather than apply it uniformly across a field. Polygon and semantic segmentation annotation are common for field-level analysis; bounding boxes are used for individual plant or pest detection.
Image Annotation Quality: How to Measure It
Intersection over Union (IoU) is the primary quality metric for bounding box and segmentation annotation. IoU measures the ratio of the overlap between the annotated region and the reference region to their combined area. A score of 1.0 means perfect agreement; industry standard minimum for object detection datasets is typically 0.5, with higher thresholds (0.75 or above) required for precision-critical applications.
For classification labels within annotation tasks — assigning the correct object class — Cohen’s kappa measures inter-annotator agreement. Kappa above 0.8 is considered strong agreement; below 0.6 signals that the label schema or guidelines need revision.
Gold standard sets — images with verified correct annotations — inserted into the annotation queue are the standard mechanism for continuous quality monitoring. Annotators do not know which items are gold items. Their accuracy on those items gives a reliable, ongoing signal about annotation quality without requiring full review of every item.
Common Image Annotation Mistakes
Loose bounding boxes are the most frequent quality problem. An annotator who draws a box that includes significant background content around the object adds noise that the model learns as part of the object’s appearance. Annotation guidelines should specify tight-fit requirements with visual examples of acceptable and unacceptable boxes.
Inconsistent class boundaries — annotating the same object type differently across the dataset — are harder to detect but more damaging. If the same type of vehicle is sometimes labelled as ‘car’ and sometimes as ‘vehicle’, the model learns a fuzzy distinction that degrades performance at the class boundary. A clear label taxonomy with examples for each class, applied consistently from the first annotation to the last, prevents this.
Skipping overlap handling creates problems for detection models. When two objects overlap, each must be annotated fully — the occluded object should be annotated to its estimated full extent, not just its visible portion. Models trained on partially annotated overlapping objects learn to ignore the occluded parts of objects in production.
Not measuring inter-annotator agreement before scaling is the process mistake that creates all of the above problems at volume. A pilot batch with agreement scoring surfaces all of these issues when they are still cheap to fix.
Frequently Asked Questions
Image annotation in machine learning is the process of adding labels, bounding boxes, segmentation masks, or other structured markers to images so that computer vision models can learn from them. The annotated images form the ground truth dataset the model trains against.
The main types are bounding box annotation (rectangular frames around objects), polygon annotation (precise outlines), semantic segmentation (class label per pixel, no instance distinction), instance segmentation (class and unique ID per object), keypoint annotation (specific coordinate markers), 3D cuboid annotation (depth and orientation for LiDAR data), and line annotation (linear features like lanes or paths). The right type depends on the model architecture and what information the model needs to make decisions.
Semantic segmentation assigns a class label to every pixel, treating all instances of that class as one region — two people both receive the ‘person’ label. Instance segmentation assigns both a class and a unique ID to each object, so the two people receive different instance identifiers. Instance segmentation is more expensive to produce and necessary for tasks involving counting, tracking, or reasoning about individual objects.
Bounding box annotation trains object detection models to locate and classify objects within an image. It is the most widely used image annotation technique because it is relatively fast to produce and sufficient for most detection tasks. It is not appropriate when objects are irregular in shape, densely overlapping, or when the model needs pixel-level boundary precision — in those cases, polygon or segmentation annotation is required.
The standard metric for bounding box and segmentation annotation quality is Intersection over Union (IoU) — the ratio of the overlap between the annotated region and the reference to their combined area. For class assignment accuracy, Cohen’s kappa measures inter-annotator agreement. Both should be tracked from the pilot batch onward, not just at final delivery.
Widely used platforms as of 2026 include Labelbox, Scale AI, SuperAnnotate, V7 (formerly Darwin), and CVAT (open source, developed by Intel). The right choice depends on annotation type support, model-assisted pre-labelling capability, inter-annotator agreement tracking, and integration with your training pipeline. Running a paid pilot with the actual dataset is the only reliable way to evaluate a tool before committing.
References
[1] Damco Group. Powering AI Breakthroughs with Data Annotation. Data annotation tools market estimated at $1.7 billion in 2025, projected to exceed $14 billion by 2034. Source: damcogroup.com, May 2026.
[2] Sama. Image Annotation Guide for Computer Vision. Segmentation techniques and autonomous vehicle use cases. Source: sama.com, February 2026.
[3] V7 Labs. Bounding Box Annotation Guide. Best practices for box fit, overlap handling, and when to use segmentation instead. Source: v7labs.com.

