Data Labelling and Data Annotation in ML: Understanding the Differences
Most ML teams use data labelling and data annotation interchangeably — and then run into trouble when one approach fails to deliver what the model actually needs. The confusion is understandable: both involve preparing raw data for training. The difference is in depth, and that depth directly affects what your model can and cannot learn.

This guide explains what separates data labelling from data annotation, when each approach fits, and how to match the right process to your ML task. As of 2026, the global data annotation and labelling market is on track to exceed $7 billion by 2029 [1] — which means the tooling, vendor options, and best practices are evolving fast. Getting the fundamentals right now avoids expensive rework later.
What Is Data Labelling in Machine Learning
Data labelling means assigning a predefined tag or category to a raw data point. The tag is usually a single value: “spam” or “not spam”, “cat” or “dog”, “positive” or “negative”. The model uses these tags to learn which features correspond to which class.
The process is fast by design. A labeller reads or views the item, picks from a fixed set of categories, and moves on. No spatial marking, no relationship mapping, no contextual explanation. Speed and scale are the core advantages.
Data labelling is the right tool when your task is binary or multi-class classification and the distinction between classes can be captured in a single tag. Email filtering, basic image sorting, and sentiment scoring at the sentence level are all well-served by labelling alone.
Typical labelling workflow:
- Define the label schema — enumerate all valid categories before touching any data
- Select a labelling platform matched to data type and team size
- Run a pilot batch with 50–100 items to test agreement across labellers
- Label at scale with quality sampling built in from the start
- Validate against a held-out gold set before releasing the dataset for training
What Is Data Annotation in Machine Learning
Data annotation is the broader process — it adds structured, contextually rich information to raw data rather than a simple category tag. Annotation can include bounding boxes drawn around objects, polygon segmentation of irregular shapes, entity spans marked in text, relationships mapped between entities, keypoints on body joints, and speaker diarisation in audio.
The added complexity is the point. An ML model trained on annotation can answer not just “what is this?” but “where is it?”, “what does it relate to?”, and “how does it behave over time?” Computer vision models for autonomous vehicles, medical imaging systems, and NLP models for information extraction all depend on rich annotation because simple tags cannot carry enough signal.
Annotation workflows involve more coordination: annotation guidelines must define edge cases, inter-annotator agreement must be measured, and review loops are standard. For tasks requiring domain knowledge — medical imaging, legal document parsing — annotators need either background in the field or continuous support from subject matter experts.
Data Labelling vs Data Annotation: Key Differences
The decision between labelling and annotation is rarely about vocabulary. It comes down to what information the model needs to make reliable predictions in production.
- Depth of output: Labelling assigns a single class. Annotation assigns structured metadata that describes location, relationships, or sequence — information that a class tag cannot encode.
- Speed and cost: Labelling is faster and cheaper per item. Annotation requires more time per item and often requires specialist annotators, which raises the cost.
- Scalability: Labelling scales well with crowdsourced or automated assistance. Annotation, especially for specialised domains, scales less easily because quality depends on annotator expertise.
- Model requirements: Classification models (logistic regression, basic CNNs, text classifiers) typically need labelling. Detection, segmentation, tracking, and relation extraction models need annotation.
- Error impact: Mislabels affect classification accuracy. Annotation errors — an incorrectly drawn bounding box, a wrong entity boundary — can silently degrade model behaviour in ways that are harder to trace.
Types of Data Annotation and When to Use Each
Understanding the annotation type is the first decision in any annotation project — before tool selection, before team sizing, before cost estimation.
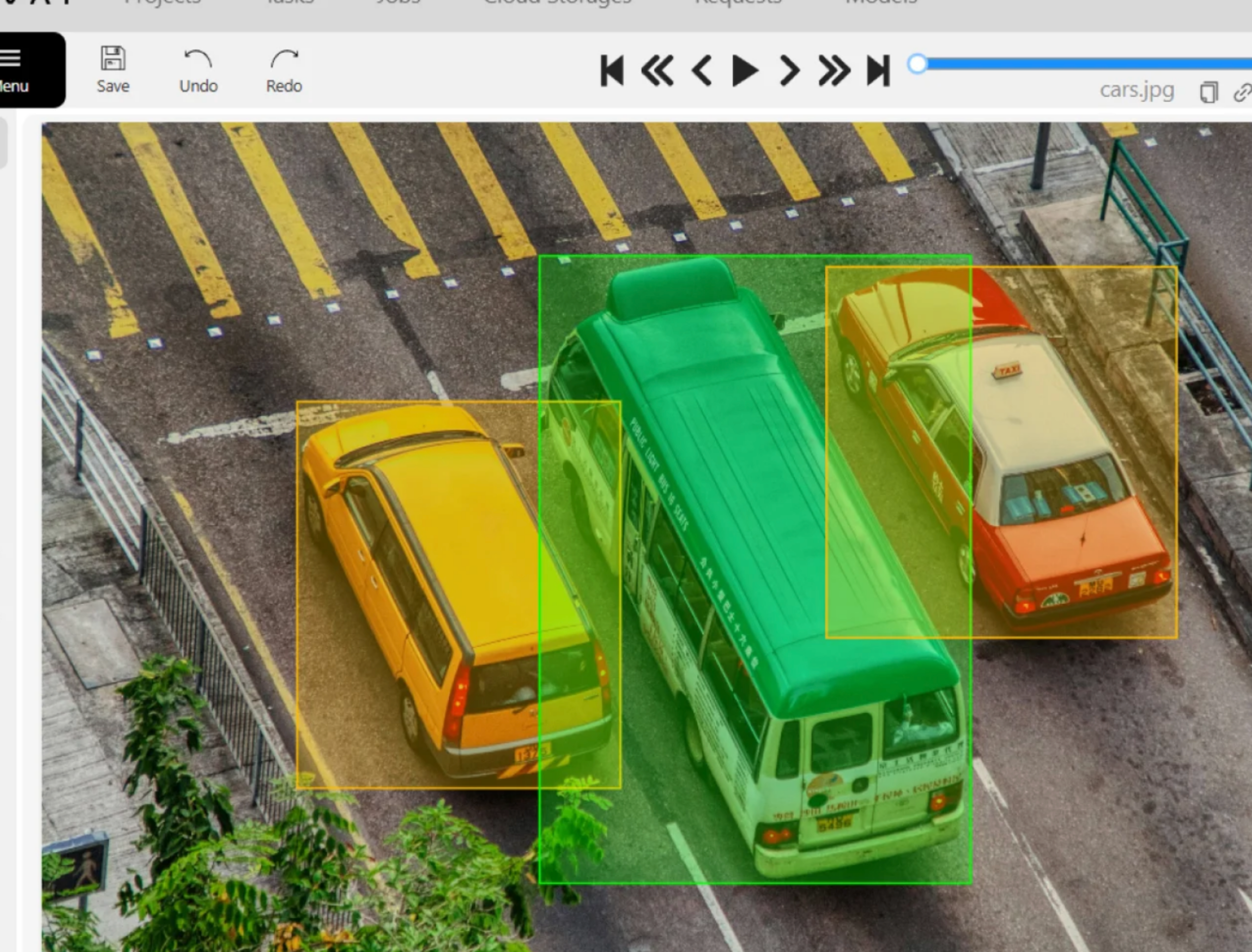
Image and video annotation
Bounding boxes mark rectangular regions around objects. They are the fastest form of image annotation and work well when object boundaries are roughly rectangular and objects do not overlap heavily. Polygon segmentation traces precise outlines — necessary for irregular shapes like people, animals, or medical structures where rectangles introduce too much noise. Semantic segmentation assigns a class to every pixel, which autonomous vehicle perception models require. Keypoint annotation marks body joints or facial landmarks for pose estimation and facial recognition tasks.
Text annotation
Named entity recognition (NER) annotation marks spans of text as people, organisations, locations, or custom domain entities. Relation annotation links entity pairs and names the relationship between them — essential for knowledge graph construction and information extraction. Sentiment annotation at the span level goes beyond sentence-level labels: it marks the specific phrase that carries sentiment and the aspect it targets. Intent and entity annotation for conversational AI requires both a class (the intent) and one or more structured fields (entities extracted from the utterance).
Audio and speech annotation
Transcription converts speech to text. Speaker diarisation identifies who speaks when. Emotion and tone annotation adds a layer of affect that transcription alone cannot carry — relevant for call centre quality models and mental health monitoring applications. Each of these tasks requires different annotator skills and different quality metrics.
How Data Labelling and Data Annotation Work Together
Most production ML pipelines use both. Labelling handles the parts of the dataset where a class tag is sufficient; annotation handles the parts where spatial or contextual detail is required.
A content moderation pipeline might label the majority of items as “safe” or “review” and then route flagged items through full annotation — bounding boxes to identify the offending region, entity spans to capture names or locations. The training set for the classifier uses labels; the training set for the detection model uses annotation.
Teams that try to replace annotation with labelling for complex tasks end up with a model that classifies correctly but cannot locate or explain what it found — a gap that only shows up at deployment. Teams that apply full annotation to every item in a simple classification task waste budget without improving model performance.
The practical principle: match the output depth to the minimum needed by the model architecture. Spend annotation effort where precision changes model behaviour in production.
Choosing Between Data Labelling and Data Annotation
Use this as a decision checklist before committing to a data preparation approach.
| Labelling is appropriate when: | Annotation is appropriate when: |
|---|---|
| The task is binary or multi-class classification | The model must locate, segment, or track objects within an item |
| A single tag per item fully describes what the model needs to learn | Relationships between elements need to be captured — entity links, causal chains, spatial dependencies |
| You need large volumes quickly and model performance does not depend on spatial precision | The domain requires specialist knowledge: medical imaging, legal text, engineering schematics |
| You need large volumes quickly and model performance does not depend on spatial precision | Your architecture is a detection, segmentation, or structured prediction model that requires bounding boxes, polygons, or entity spans as training targets |
A third question is often overlooked: what level of inter-annotator agreement is acceptable? Labelling tasks with clear criteria typically achieve agreement above 90% with trained annotators. Complex annotation tasks — especially those requiring judgement about ambiguous boundaries — may require multiple annotators per item and a consensus or adjudication step. Build that cost into the project plan from the start.
Data Quality: The Factor That Overrides Everything Else
Poor data quality is the primary technical barrier to AI and ML implementation, according to the 2023 Global Trends in AI Report by S&P Global [2]. Mislabelling introduces systematic bias; weak annotation introduces noise. Both problems compound as the dataset grows.
Quality control for labelling typically involves spot-checking a sample of completed items against a gold standard set with known correct answers. A 5% quality sample is a common minimum; projects with higher stakes or lower annotator agreement should increase this.
Quality control for annotation requires more: agreement scoring between annotators (Cohen’s kappa for classification, IoU for bounding boxes), regular calibration sessions to align annotators on edge cases, and review queues for items flagged during automated validation.
Data scientists report spending up to 80% of their time on data-related tasks — labelling, augmenting, and validating training data [3]. Investing in a clear annotation guide, a structured review process, and a pilot batch before full-scale work is the single most reliable way to reduce that burden without sacrificing quality.
Common Mistakes Teams Make with Data Labelling and Annotation
Applying labelling where annotation is needed is the most common and expensive mistake. The model trains fine on the labelled dataset and then fails in production because it cannot localise the object or extract the entity — the label told it what, but not where or how.
Skipping the pilot batch is the second. Guidelines that seem clear in a document almost always surface ambiguities in practice — images where the object boundary is contested, text spans where the entity type is disputed. A pilot batch of 50–100 items run by multiple annotators surfaces these ambiguities before they propagate across the full dataset.
Not measuring inter-annotator agreement is the third. If two annotators applying the same guidelines disagree on 30% of items, the training data is noisy at scale. Agreement measurement is not overhead — it is the signal that the guidelines are working.
Finally, assuming the labelling or annotation schema is fixed. Models change, task definitions evolve, and production data drifts from the training distribution. Labelling pipelines should be designed to evolve with the project, not treated as a one-time deliverable.
Frequently Asked Questions
Data labelling and data annotation are not the same, though the terms are often used interchangeably. Labelling assigns a single predefined tag to a data point. Annotation adds richer, structured metadata — such as bounding boxes, entity spans, or relationships — that carries more information than a tag alone. Labelling is a subset of annotation.
Data labelling is faster. Assigning a category from a fixed list takes seconds per item; drawing a bounding box, tracing a polygon, or marking entity relationships takes minutes. For large-scale classification tasks, labelling is the practical choice. Annotation is slower because it encodes more information per item.
Object detection, image segmentation, pose estimation, named entity recognition with relation mapping, speech diarisation, and any task where the model needs to locate or link elements within an item — not just classify the item as a whole. Autonomous vehicles, medical imaging, and information extraction from documents are the most common domains.
Annotation costs more per item because it requires more time and often more specialised annotators. The cost gap widens with domain complexity: general image labelling is inexpensive; medical image segmentation with clinical annotators can cost 20–50 times more per item. Budget planning should start with the annotation type and the annotator expertise required, not with a per-item rate estimate.
Automation can accelerate both, but cannot replace human review for quality assurance. Model-assisted annotation — where a pre-trained model generates initial suggestions that annotators correct — cuts annotation time significantly for well-defined tasks. Fully automated labelling is viable for structured data with clear rules. For ambiguous, high-stakes, or novel domains, human judgement remains essential.
Outsourced annotation makes sense when you need volume quickly, the task does not require proprietary domain knowledge, and security constraints allow it. According to Cognilytica research, companies spend about five times more on internal labelling than on third-party services [4]. In-house annotation is preferable for sensitive data, highly specialised domains, or tasks where annotators need to understand the product deeply. Many teams use a hybrid: outsource high-volume general tasks, keep specialised or sensitive tasks in-house.
Semantic segmentation assigns a class to every pixel without distinguishing individual objects — all pixels belonging to “person” get the same label. Instance segmentation assigns a class and a unique identity to each object, so two people in the same image receive different instance IDs. Instance segmentation is more expensive to produce but necessary for tasks like counting objects or tracking individuals across frames.
References
[1] Research and Markets. Data Annotation and Labeling Market Report. 2024–2029 forecast. Source: Conectys blog, April 2026.
[2] S&P Global. 2023 Global Trends in AI Report. Data management cited as the primary technical problem in AI and ML implementation. Source: Toloka.ai.
[3] Sama. Top 10 Data Labeling Frequently Asked Questions. Data scientists spend up to 80% of their time on data-related tasks. 2026.
[4] Cognilytica / Innodata. Companies spend approximately five times more on internal data labelling than on third-party services. Source: Innodata.com.

